Troubleshoot Snapshots
When a snapshot fails, a support bundle will be collected and stored automatically. Because this is a point-in-time collection of all logs and system state at the time of the failed snapshot, this is a good place to view the logs.
Velero is Crashing
If Velero is crashing and not starting, some common causes are:
Invalid Cloud Credentials
Symptom
You see the following error message from Velero when trying to configure a snapshot.
time="2020-04-10T14:22:24Z" level=info msg="Checking existence of namespace" logSource="pkg/cmd/server/server.go:337" namespace=velero
time="2020-04-10T14:22:24Z" level=info msg="Namespace exists" logSource="pkg/cmd/server/server.go:343" namespace=velero
time="2020-04-10T14:22:27Z" level=info msg="Checking existence of Velero custom resource definitions" logSource="pkg/cmd/server/server.go:372"
time="2020-04-10T14:22:31Z" level=info msg="All Velero custom resource definitions exist" logSource="pkg/cmd/server/server.go:406"
time="2020-04-10T14:22:31Z" level=info msg="Checking that all backup storage locations are valid" logSource="pkg/cmd/server/server.go:413"
An error occurred: some backup storage locations are invalid: backup store for location "default" is invalid: rpc error: code = Unknown desc = NoSuchBucket: The specified bucket does not exist
status code: 404, request id: BEFAE2B9B05A2DCF, host id: YdlejsorQrn667ziO6Xr6gzwKJJ3jpZzZBMwwMIMpWj18Phfii6Za+dQ4AgfzRcxavQXYcgxRJI=
Cause
If the cloud access credentials are invalid or do not have access to the location in the configuration, Velero will crashloop. The Velero logs will be included in a support bundle, and the message will look like this.
Solution
Replicated recommends that you validate the access key / secret or service account json.
Invalid Top-level Directories
Symptom
You see the following error message when Velero is starting:
time="2020-04-10T14:12:42Z" level=info msg="Checking existence of namespace" logSource="pkg/cmd/server/server.go:337" namespace=velero
time="2020-04-10T14:12:42Z" level=info msg="Namespace exists" logSource="pkg/cmd/server/server.go:343" namespace=velero
time="2020-04-10T14:12:44Z" level=info msg="Checking existence of Velero custom resource definitions" logSource="pkg/cmd/server/server.go:372"
time="2020-04-10T14:12:44Z" level=info msg="All Velero custom resource definitions exist" logSource="pkg/cmd/server/server.go:406"
time="2020-04-10T14:12:44Z" level=info msg="Checking that all backup storage locations are valid" logSource="pkg/cmd/server/server.go:413"
An error occurred: some backup storage locations are invalid: backup store for location "default" is invalid: Backup store contains invalid top-level directories: [other-directory]
Cause
This error message is caused when Velero is attempting to start, and it is configured to use a reconfigured or re-used bucket.
When configuring Velero to use a bucket, the bucket cannot contain other data, or Velero will crash.
Solution
Configure Velero to use a bucket that does not contain other data.
Node Agent is Crashing
If the node-agent Pod is crashing and not starting, some common causes are:
Metrics Server is Failing to Start
Symptom
You see the following error in the node-agent logs.
time="2023-11-16T21:29:44Z" level=info msg="Starting metric server for node agent at address []" logSource="pkg/cmd/cli/nodeagent/server.go:229"
time="2023-11-16T21:29:44Z" level=fatal msg="Failed to start metric server for node agent at []: listen tcp :80: bind: permission denied" logSource="pkg/cmd/cli/nodeagent/server.go:236"
Cause
This is a result of a known issue in Velero 1.12.0 and 1.12.1 where the port is not set correctly when starting the metrics server. This causes the metrics server to fail to start with a permission denied error in environments that do not run MinIO and have Host Path, NFS, or internal storage destinations configured. When the metrics server fails to start, the node-agent Pod crashes. For more information about this issue, see the GitHub issue details.
Solution
Replicated recommends that you either upgrade to Velero 1.12.2 or later, or downgrade to a version earlier than 1.12.0.
Snapshot Creation is Failing
Timeout Error when Creating a Snapshot
Symptom
You see a backup error that includes a timeout message when attempting to create a snapshot. For example:
Error backing up item
timed out after 12h0m0s
Cause
This error message appears when the node-agent (restic) Pod operation timeout limit is reached. In Velero v1.4.2 and later, the default timeout is 240 minutes.
Restic is an open-source backup tool. Velero integrates with Restic to provide a solution for backing up and restoring Kubernetes volumes. For more information about the Velero Restic integration, see File System Backup in the Velero documentation.
Solution
Use the kubectl Kubernetes command-line tool to patch the Velero deployment to increase the timeout:
Velero version 1.10 and later:
kubectl patch deployment velero -n velero --type json -p '[{"op":"add","path":"/spec/template/spec/containers/0/args/-","value":"--fs-backup-timeout=TIMEOUT_LIMIT"}]'
Velero versions less than 1.10:
kubectl patch deployment velero -n velero --type json -p '[{"op":"add","path":"/spec/template/spec/containers/0/args/-","value":"--restic-timeout=TIMEOUT_LIMIT"}]'
Replace TIMEOUT_LIMIT with a length of time for the node-agent (restic) Pod operation timeout in hours, minutes, and seconds. Use the format 0h0m0s. For example, 48h30m0s.
The timeout value reverts back to the default value if you rerun the velero install command.
Memory Limit Reached on the node-agent Pod
Symptom
The node-agent (restic) Pod is killed by the Linux kernel Out Of Memory (OOM) killer or snapshots are failing with errors simlar to:
pod volume backup failed: ... signal: killed
Cause
Velero sets default limits for the velero Pod and the node-agent (restic) Pod during installation. There is a known issue with Restic that causes high memory usage, which can result in failures during snapshot creation when the Pod reaches the memory limit.
For more information, see the Restic backup — OOM-killed on raspberry pi after backing up another computer to same repo issue in the restic GitHub repository.
Solution
Increase the default memory limit for the node-agent (restic) Pod if your application is particularly large. For more information about configuring Velero resource requests and limits, see Customize resource requests and limits in the Velero documentation.
For example, the following kubectl commands will increase the memory limit for the node-agent (restic) daemon set from the default of 1Gi to 2Gi.
Velero 1.10 and later:
kubectl -n velero patch daemonset node-agent -p '{"spec":{"template":{"spec":{"containers":[{"name":"node-agent","resources":{"limits":{"memory":"2Gi"}}}]}}}}'
Velero versions earlier than 1.10:
kubectl -n velero patch daemonset restic -p '{"spec":{"template":{"spec":{"containers":[{"name":"restic","resources":{"limits":{"memory":"2Gi"}}}]}}}}'
Alternatively, you can potentially avoid the node-agent (restic) Pod reaching the memory limit during snapshot creation by running the following kubectl command to lower the memory garbage collection target percentage on the node-agent (restic) daemon set:
Velero 1.10 and later:
kubectl -n velero set env daemonset/node-agent GOGC=1
Velero versions earlier than 1.10:
kubectl -n velero set env daemonset/restic GOGC=1
At least one source file could not be read
Symptom
You see the following error in Velero logs:
Error backing up item...Warning: at least one source file could not be read
Cause
There are file changes between Restic's initial scan of the volume and during the backup to Restic store.
Solution
To resolve this issue, do one of the following:
- Use hooks to export data to an EmptyDir volume and include that in the backup instead of the primary PVC volume. See Configure Backup and Restore Hooks for Snapshots.
- Freeze the file system to ensure all pending disk I/O operations have completed prior to taking a snapshot. For more information, see Hook Example with fsfreeze in the Velero documentation.
Snapshot Restore is Failing
Service NodePort is Already Allocated
Symptom
In the Replicated KOTS Admin Console, you see an Application failed to restore error message that indicates the port number for a static NodePort is already in use. For example:
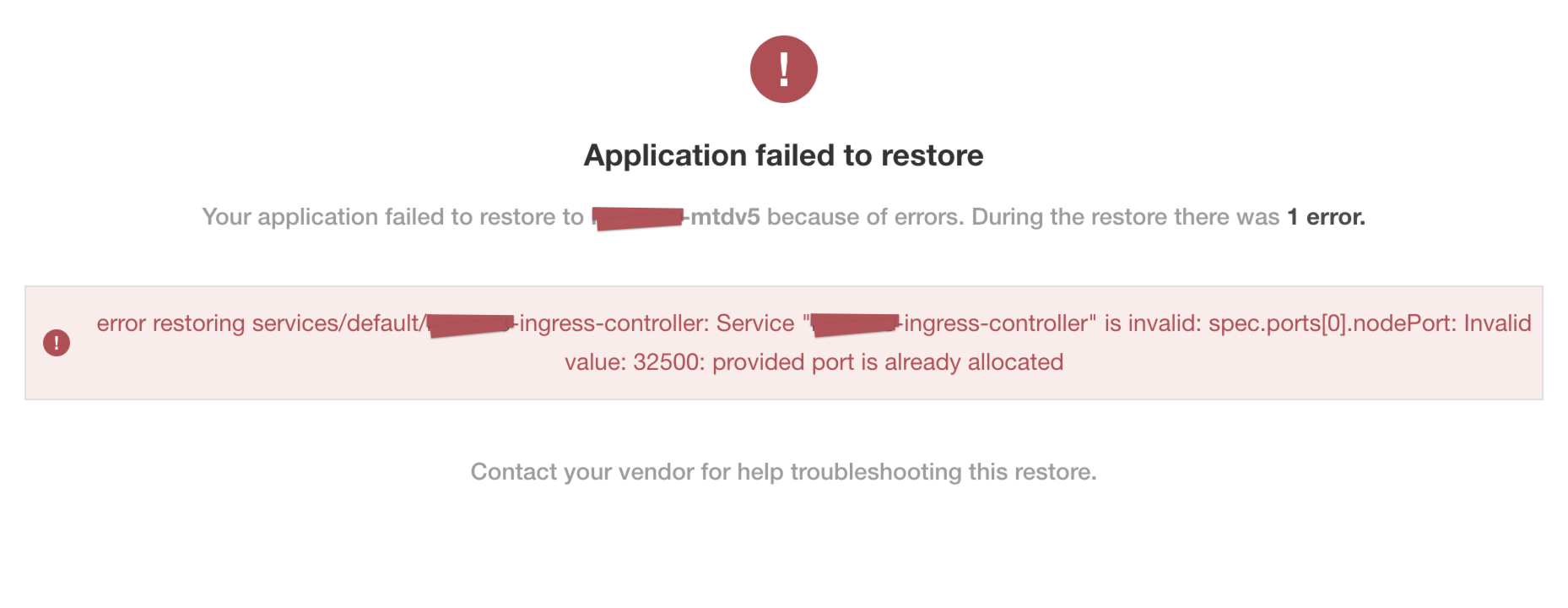
View a larger version of this image
Cause
There is a known issue in Kubernetes versions earlier than version 1.19 where using a static NodePort for services can collide in multi-primary high availability setups when recreating the services. For more information about this known issue, see https://github.com/kubernetes/kubernetes/issues/85894.
Solution
This issue is fixed in Kubernetes version 1.19. To resolve this issue, upgrade to Kubernetes version 1.19 or later.
For more infromation about the fix, see https://github.com/kubernetes/kubernetes/pull/89937.
Partial Snapshot Restore is Stuck in Progress
Symptom
In the Admin Console, you see at least one volume restore progress bar frozen at 0%. Example Admin Console display:
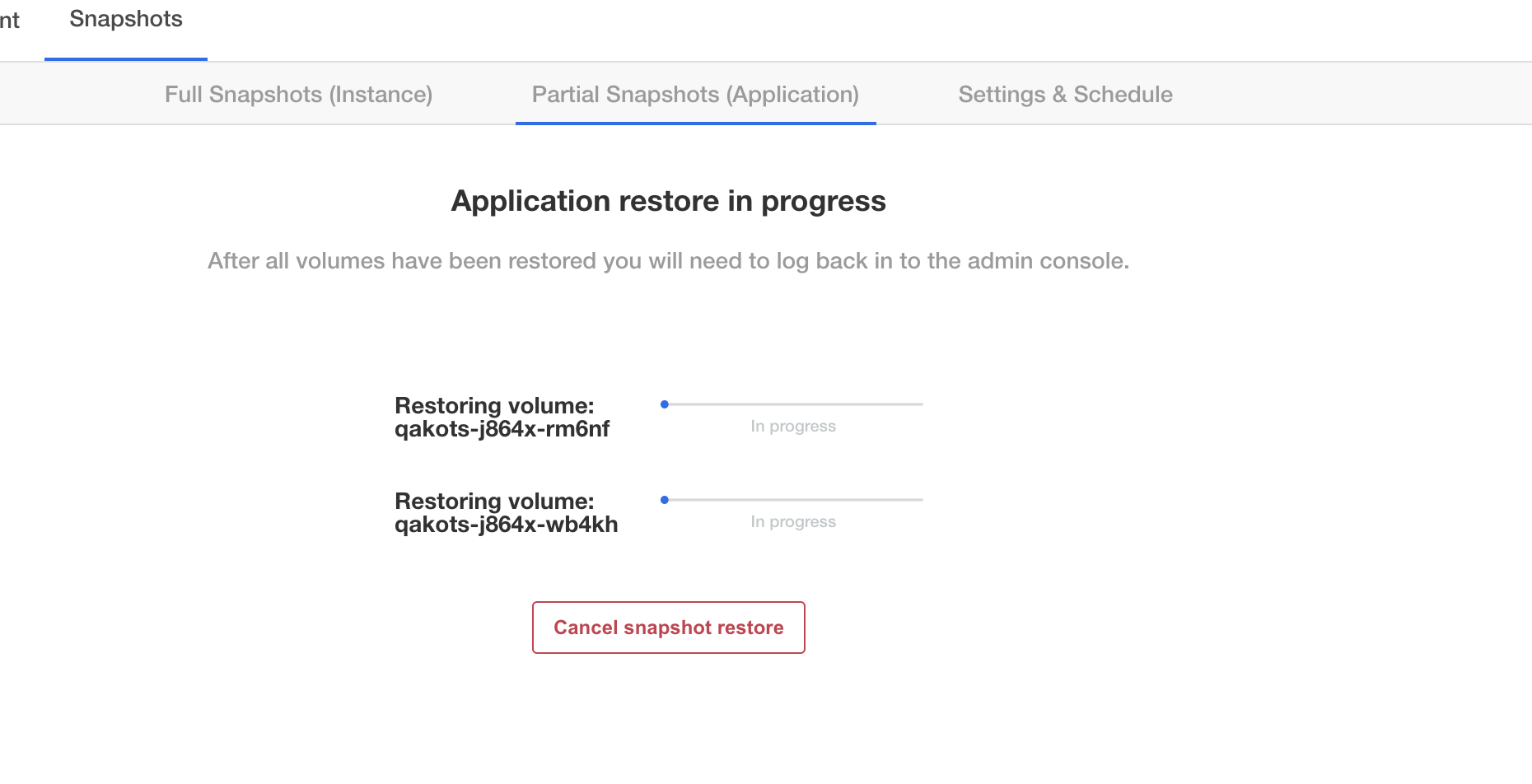
You can confirm this is the same issue by running kubectl get pods -n <application namespace>, and you should see at least one pod stuck in initialization:
NAME READY STATUS RESTARTS AGE
example-mysql-0 0/1 Init:0/2 0 4m15s #<- the offending pod
example-nginx-77b878b4f-zwv2h 3/3 Running 0 4m15s
Cause
We have seen this issue with Velero version 1.5.4 and opened up this issue with the project to inspect the root cause: https://github.com/vmware-tanzu/velero/issues/3686. However we have not experienced this using Velero 1.6.0 or later.
Solution
Upgrade Velero to 1.9.0. You can upgrade using Replicated kURL. Or, to follow the Velero upgrade instructions, see Upgrading to Velero 1.9 in the Velero documentation.
Partial Snapshot Restore Finishes with Warnings
Symptom
In the Admin Console, when the partial snapshot restore completes, you see warnings indicating that Endpoint resources were not restored:
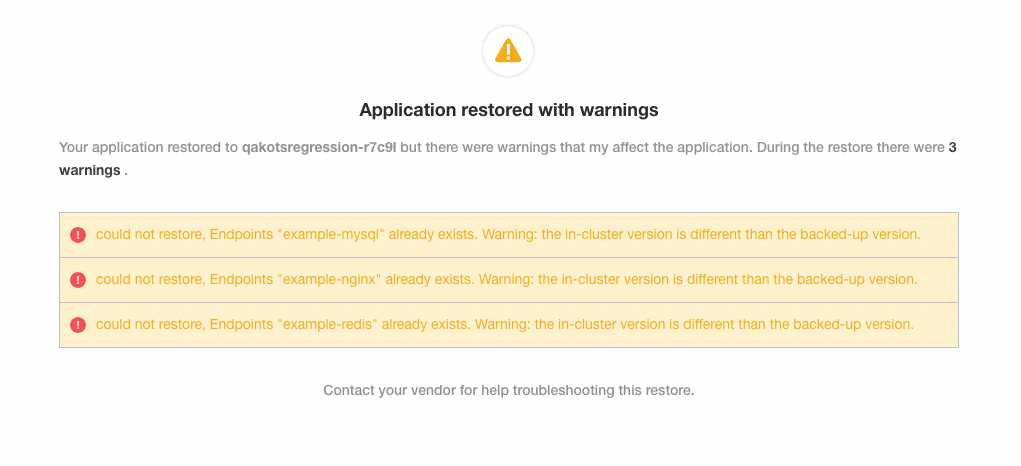
Cause
The resource restore priority was changed in Velero 1.10.3 and 1.11.0, which leads to this warning when restoring Endpoint resources. For more information about this issue, see the issue details in GitHub.
Solution
These warnings do not necessarily mean that the restore itself failed. The endpoints likely do exist as they are created by Kubernetes when the related Service resources were restored. However, to prevent encountering these warnings, use Velero version 1.11.1 or later.